Learn how to use MarkdownDB with our First Tutorial!

Ola Rubaj
We've just released our first tutorial that covers the fundamentals of MarkdownDB - our new package for treating markdown files as a database. If you've been curious about how to manage your markdown files more effectively, this tutorial is an excellent starting point!
What is MarkdownDB?
MarkdownDB can parse your markdown files, extract structured data (such as frontmatter, tags, back- and forward links and more), and create an index in a local SQLite database. It also provides a lightweight JavaScript API for querying the database and importing files into your application. With MarkdownDB, you have a powerful tool that allows you to efficiently query your markdown data.
What you're going to learn
This tutorial guides you through the steps of creating a small project catalog. In our case, we used our open-source projects on GitHub - but you could use anything! We use simple markdown files to describe each project and then display them with the MarkdownDB package.
Step 1: Create a markdown file for each project
First, let's create a markdown file for each project. You can use real project details or make up some examples. For the sake of this tutorial, we'll create files for some of the projects we've built at Datopian.
mkdir projects
cd projects
touch markdowndb.md portaljs.md flowershow.md datapipes.md giftless.md data-cli.md
In each file we'll write some short info about a given project, like so:
# What is MarkdownDB
MarkdownDB is a javascript library for treating markdown files as a database -- as a "MarkdownDB". Specifically, it:
- Parses your markdown files to extract structured data (frontmatter, tags, etc) and creates an index in a local SQLite database
- Provides a lightweight javascript API for querying the database and importing files into your application
Step 2: Index markdown files into SQLite database
Once we have prepared our markdown files, we can store them (or more precisely - their metadata) in a database, so that we can then query it later for specific project files.
# npx mddb <path-to-folder-with-md-files>
npx mddb ./projects
The above command will output a markdown.db file in the directory where it was executed. So, in our case, the folder structure will look like this:
.
├── markdown.db
└── projects
├── data-cli.md
├── ...
└── portaljs.md
Step 3: Explore the SQLite database
Now, let's explore the database. We can do it with any SQLite viewer, e.g. https://sqlitebrowser.org/. When we open the markdown.db file in the viewer, we'll see a list of tables:
files: containing metadata of our markdown,file_tags: containing tags set in the frontmatter of our markdown files,links: containing wiki links, i.e. links between our markdown files,tags: containing all tags used in our markdown files.
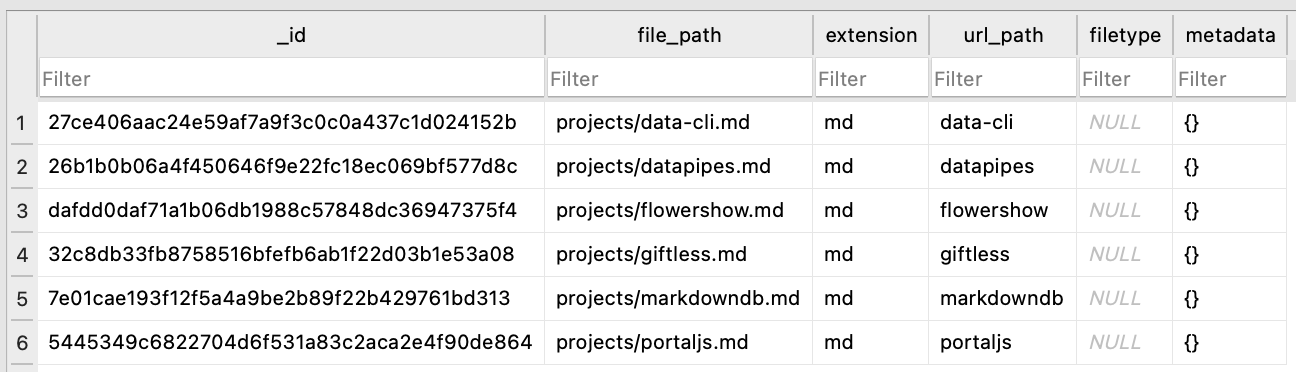
In our case, the files table will look like this:
You can also explore the database from the command line, e.g.:
sqlite3 markdown.db
And then run SQL queries, e.g.:
SELECT * FROM files;
Which will output:
27ce406aac24e59af7a9f3c0c0a437c1d024152b|projects/data-cli.md|md|data-cli||{}
26b1b0b06a4f450646f9e22fc18ec069bf577d8c|projects/datapipes.md|md|datapipes||{}
dafdd0daf71a1b06db1988c57848dc36947375f4|projects/flowershow.md|md|flowershow||{}
32c8db33fb8758516bfefb6ab1f22d03b1e53a08|projects/giftless.md|md|giftless||{}
7e01cae193f12f5a4a9be2b89f22b429761bd313|projects/markdowndb.md|md|markdowndb||{}
5445349c6822704d6f531a83c2aca2e4f90de864|projects/portaljs.md|md|portaljs||{}
Step 4: Query the database in the Node.js app
Now, let's write a simple script that will query the database for our projects and display them on the terminal.
First, let's create a new Node.js project:
mkdir projects-list
cd projects-list
npm init -y
Then, let's install the mddb package:
npm install mddb
Now, let's create a new file index.js and add the following code:
import { MarkdownDB } from 'mddb';
// change this to the path to your markdown.db file
const dbPath = 'markdown.db';
const client = new MarkdownDB({
client: 'sqlite3',
connection: {
filename: dbPath,
},
});
const mddb = await client.init();
// get all projects
const projects = await mddb.getFiles();
console.log(JSON.stringify(projects, null, 2));
process.exit(0);
Since we're using ES6 modules, we also need to add "type": "module" to our package.json file.
Before we run the above script, we need to make sure that the dbPath variable is pointing to our markdown.db file. If you want to store the database outside of your project folder, you can update the dbPath variable to point to the correct location. If you want to have it inside your project folder, you can copy it there, or simply re-run the npx mddb <path-to-markdown-folder> command from within your project folder.
Now, let's run the script:
node index.js
It should output the JSON with all our projects.
[
{
"_id": "7e01cae193f12f5a4a9be2b89f22b429761bd313",
"file_path": "projects/markdowndb.md",
"extension": "md",
"url_path": "markdowndb",
"filetype": null,
"metadata": {}
},
...
]
Step 5: Add metadata to project files
Now, let's add some metadata to our project files. We'll use frontmatter for that. Since we're creating a catalog of our GitHub projects, we'll add the following frontmatter fields to each file:
---
name: markdowndb
description: Javascript library for treating markdown files as a database.
stars: 6
forks: 0
---
After adding the metadata, we need to re-index our markdown files into the database:
npx mddb ../projects
Now, if we run our script again, we'll see that the metadata field in the output contains the metadata we've added to our project files:
[
{
"_id": "7e01cae193f12f5a4a9be2b89f22b429761bd313",
"file_path": "projects/markdowndb.md",
"extension": "md",
"url_path": "markdowndb",
"metadata": {
"name": "markdowndb",
"description": "Javascript library for treating markdown files as a database",
"stars": 6,
"forks": 0
}
},
...
]
Step 6: Pretty print the output
Now, let's make the output a bit more readable. We'll use the columnify package for that:
npm install columnify
And then we'll update our index.js file:
import { MarkdownDB } from 'mddb';
import columnify from 'columnify';
const dbPath = 'markdown.db';
const client = new MarkdownDB({
client: 'sqlite3',
connection: {
filename: dbPath,
},
});
const mddb = await client.init();
const projects = await mddb.getFiles();
// console.log(JSON.stringify(projects, null, 2));
const projects2 = projects.map((project) => {
const { file_path, metadata } = project;
return {
file_path,
...metadata,
};
});
const columns = columnify(projects2, {
truncate: true,
columnSplitter: ' | ',
config: {
description: {
maxWidth: 80,
},
},
});
console.log('\n');
console.log(columns);
console.log('\n');
process.exit(0);
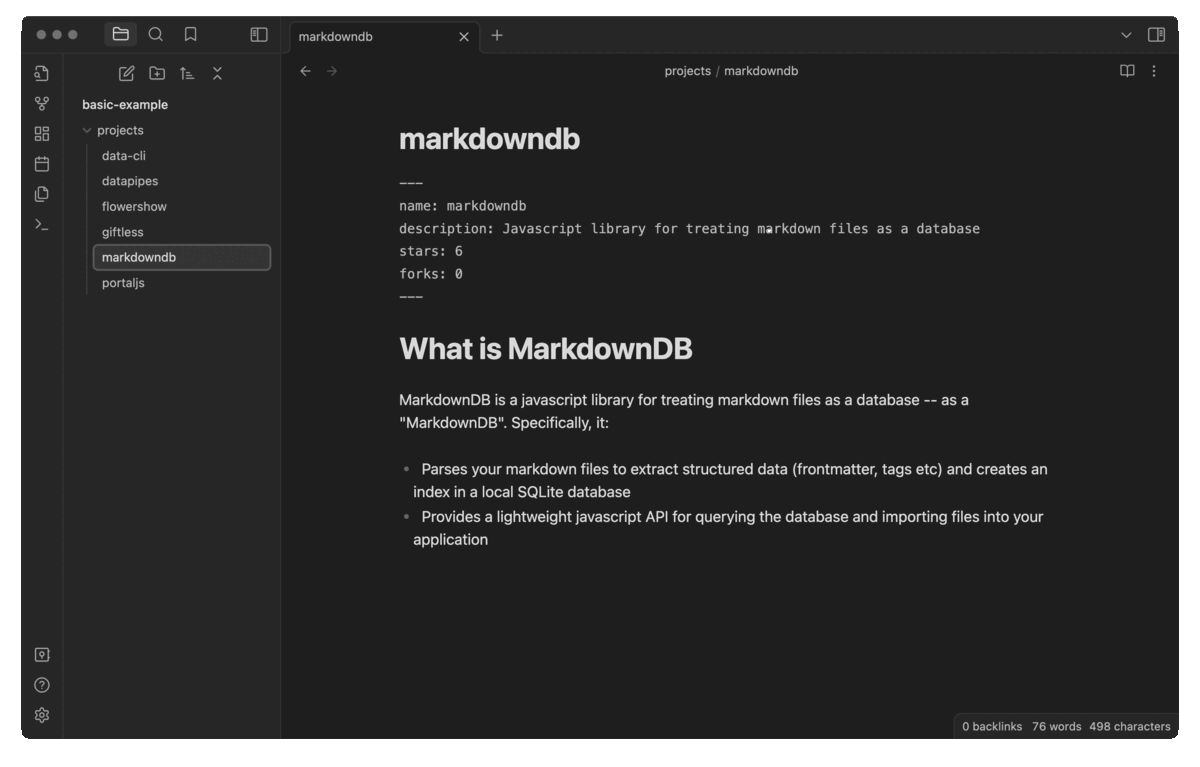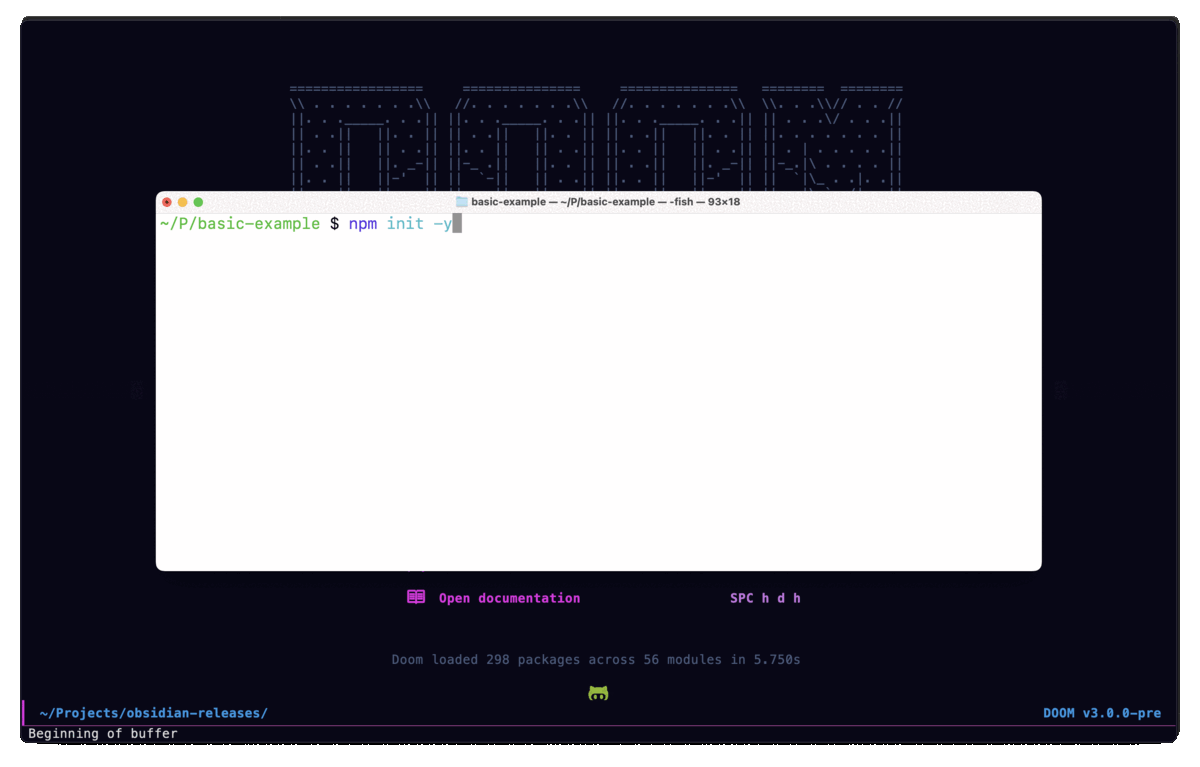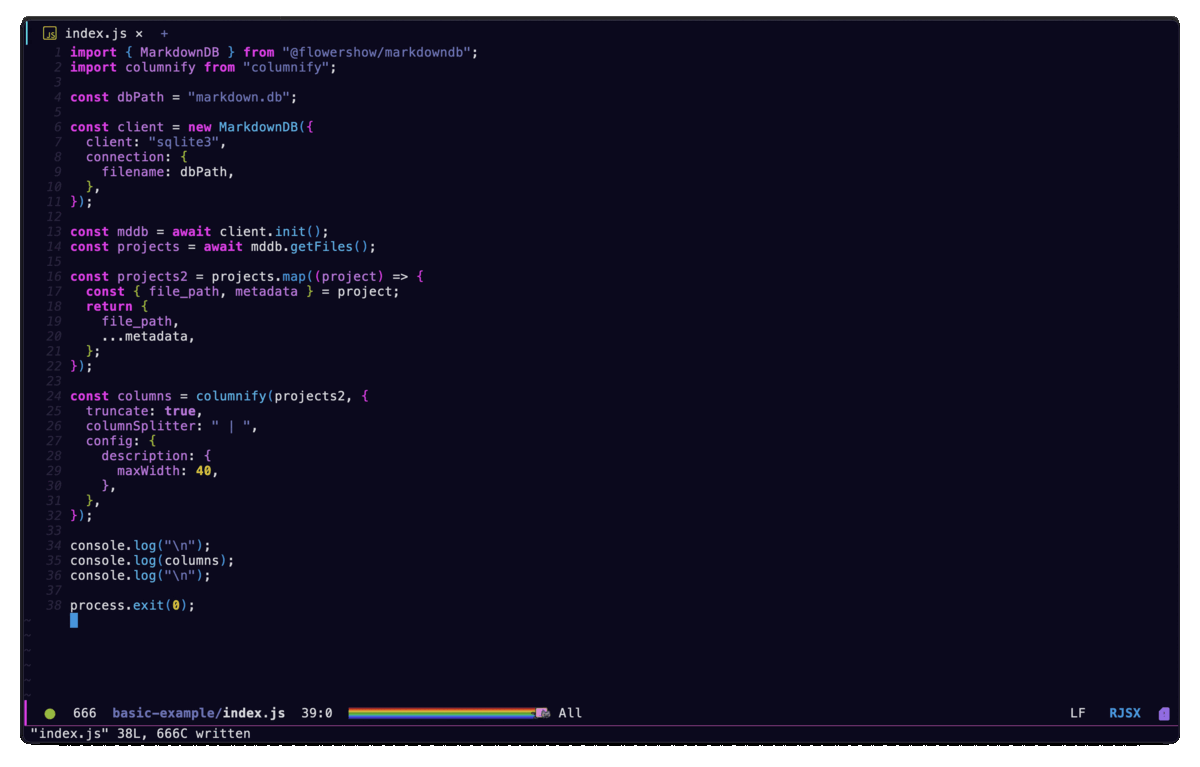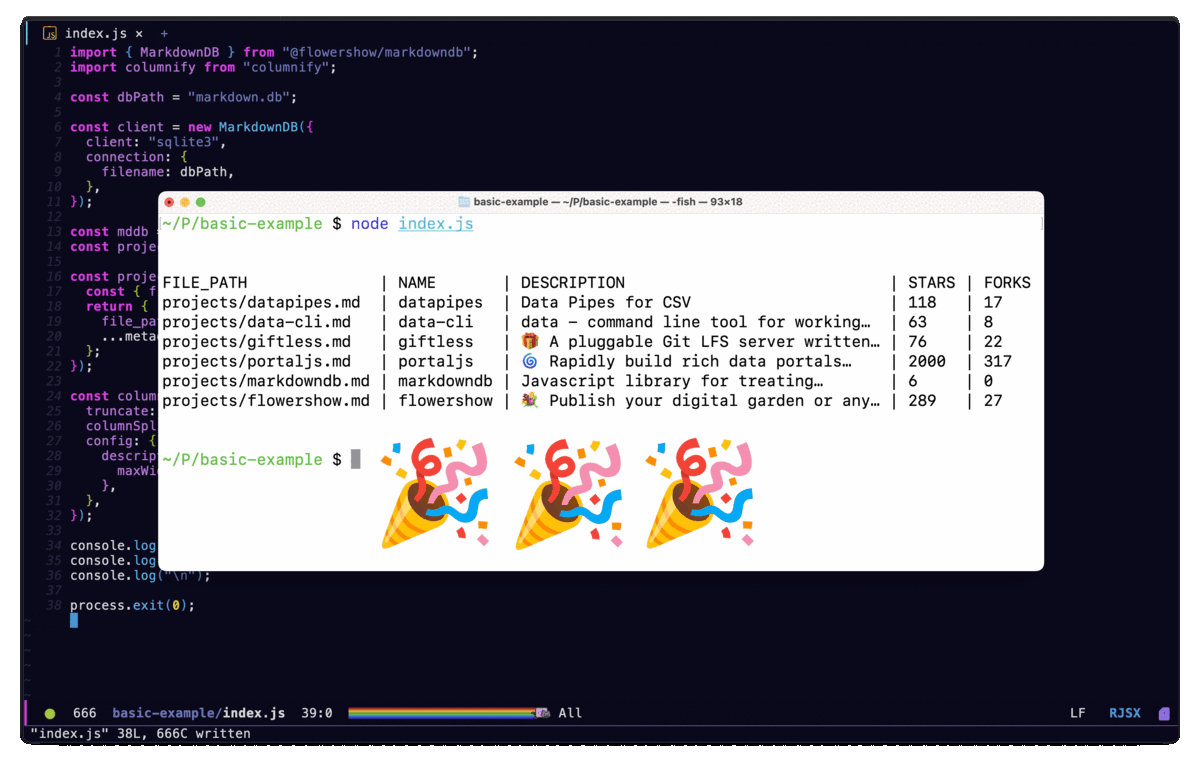
The above script will output the following to the terminal:

Done!
That's it! We've just created a simple catalog of our GitHub projects using markdown files and the MarkdownDB package. You can find the full code for this tutorial here.
We look forward to seeing the amazing applications you'll build with this tool!
Happy coding!